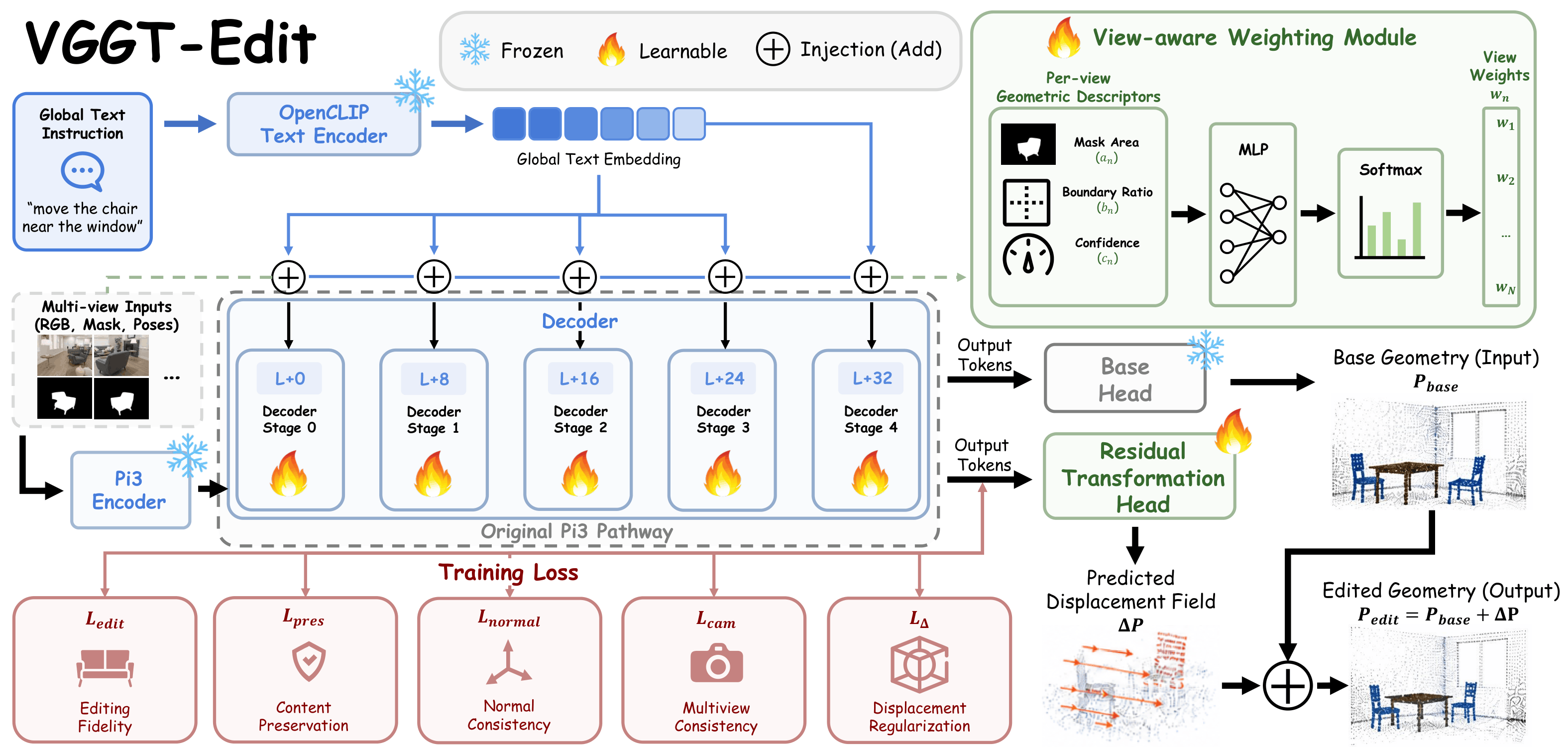
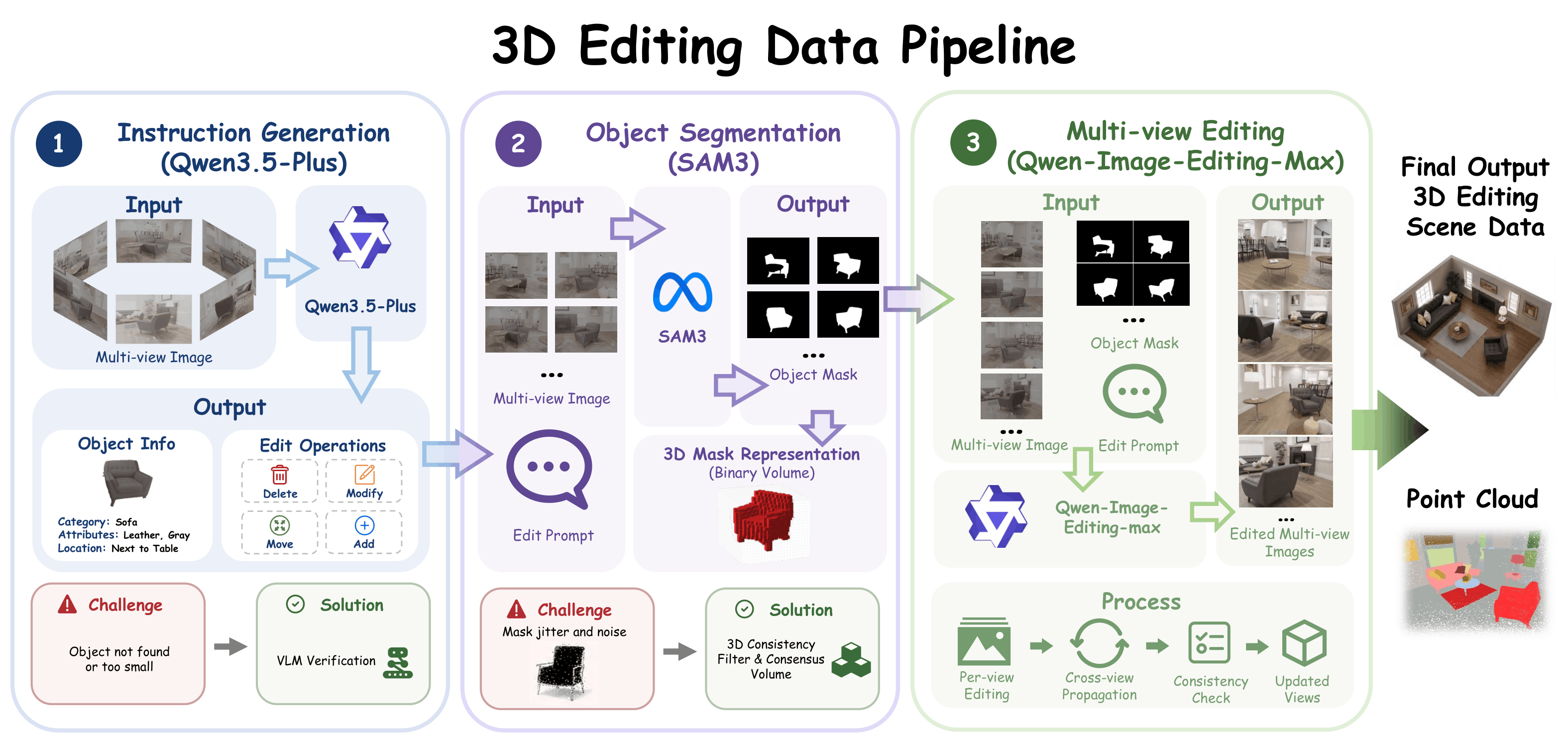
Overview
Existing 3D editing pipelines often rely on multi-view 2D editing and re-projection, which leads to geometric inconsistency, drifting backgrounds, and unstable results. VGGT-Edit instead performs editing directly in native 3D space.
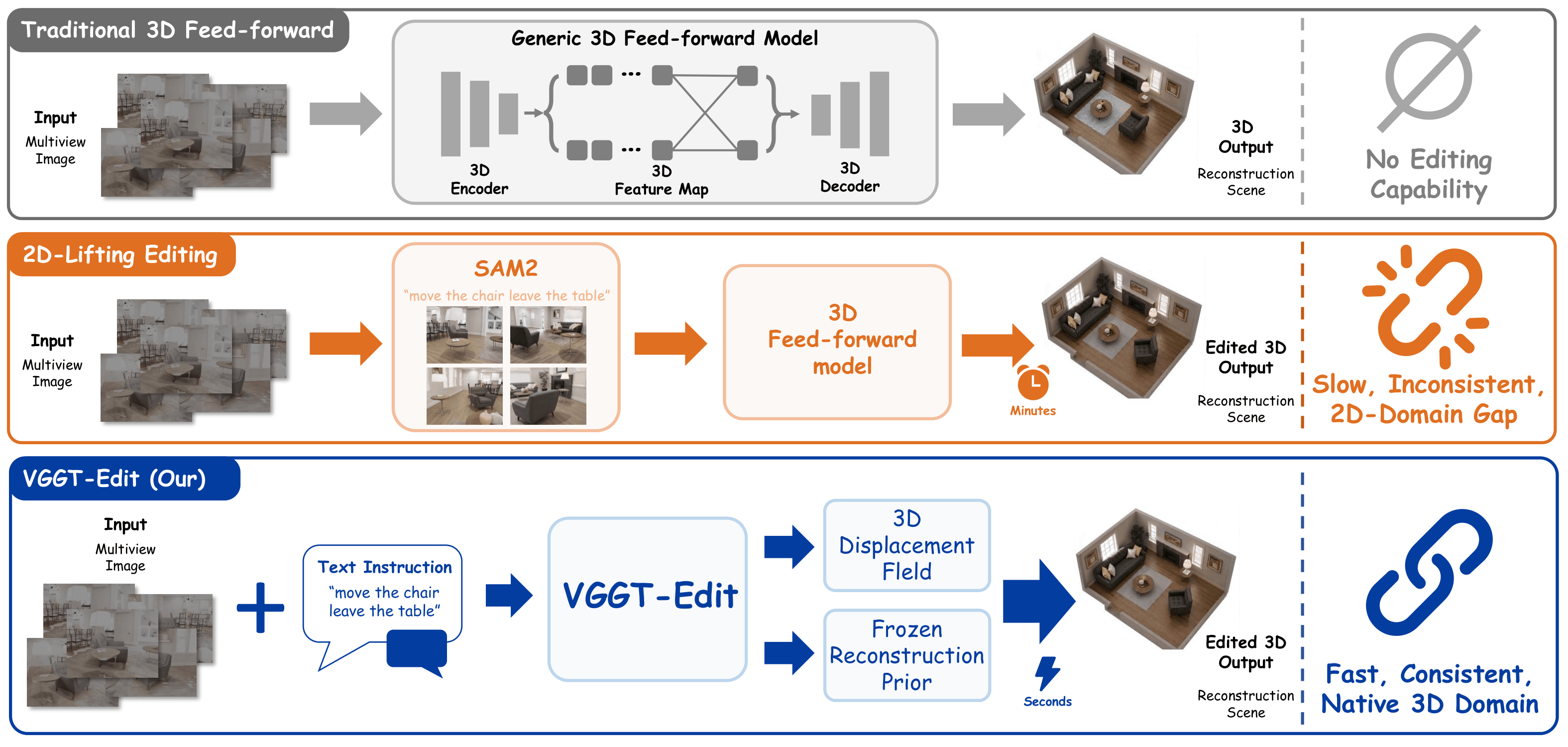
Figure 1. Comparison between existing 3D editing pipelines and VGGT-Edit.
Existing methods rely on multi-view 2D editing, while VGGT-Edit performs editing directly in native 3D space.
Native 3D Editing
Avoids 2D lifting pipelines and performs scene editing directly in geometry space.
Feed-Forward Inference
Maintains low-latency editing with stable performance across different scenes.
View Consistency
Produces coherent multi-view editing results while preserving structural integrity.
Interactive Editing
Enables practical real-time 3D scene manipulation for spatial intelligence systems.